In this post, I am going to talk about some of the limit theorems which are building blocks of statistical applications but often they work behind the curtain, users without being aware of it being used. I am not going to go into the proofs rather I would provide you with some insights about them.
Sketch of the article:
- Some inequalities
- Brief discussion on types of convergence
- What do we mean by iid random sample?
- Law of large numbers
- Central limit theorem
- References
Some inequalities
Let 
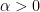
![P(X \geq \alpha) \leq \frac{1}{\alpha}E[X]](https://s0.wp.com/latex.php?latex=P%28X+%5Cgeq+%5Calpha%29+%5Cleq+%5Cfrac%7B1%7D%7B%5Calpha%7DE%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)
![E[X]=\int_{-\infty}^{\infty} x f_X(x) dx](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+x+f_X%28x%29+dx&bg=ffffff&fg=000&s=0&c=20201002)



This is what we wanted to prove. Now based on this inequality, we can derive Markov’s inequality and Chebyshev’s inequality.
Markov’s inequality: ![P(|X| \geq \alpha) \leq \frac{1}{\alpha^k}E[|X|^k]](https://s0.wp.com/latex.php?latex=P%28%7CX%7C+%5Cgeq+%5Calpha%29+%5Cleq+%5Cfrac%7B1%7D%7B%5Calpha%5Ek%7DE%5B%7CX%7C%5Ek%5D&bg=ffffff&fg=000&s=0&c=20201002)
the proof for this is essentially similar to the above case, only thing that changes here is that we need to evaluate ![E[|X|^k]](https://s0.wp.com/latex.php?latex=E%5B%7CX%7C%5Ek%5D&bg=ffffff&fg=000&s=0&c=20201002)
Chebyshev’s inequality: ![P(|X-E[X]| \geq \alpha) \leq \frac{Var(X)}{\alpha^2}](https://s0.wp.com/latex.php?latex=P%28%7CX-E%5BX%5D%7C+%5Cgeq+%5Calpha%29+%5Cleq+%5Cfrac%7BVar%28X%29%7D%7B%5Calpha%5E2%7D&bg=ffffff&fg=000&s=0&c=20201002)
now here you can easily make changes from preceding inequality to arrive at this position. Like A. Markov, Pafnuty Chebyshev was also a Russian mathematician, in fact he was a teacher of Markov and he is also regarded as the founding father of the Russian mathematics. He worked in the number theory and the probability theory.
Brief discussion on types of convergence
We are going to talk about the convergence of a sequence of random variables. We would be discussing three such types, one is the convergence in the probability, the second is the almost sure convergence and the third is going to be the convergence in the distribution.
A sequence of random variables, 
for every 


The convergence in probability simply means that the probability of difference becomes smaller and smaller with increasing 
A sequence of random variables,
for every 
The almost sure convergence means that the set where convergence fails is of measure zero, i.e. probability is zero for that set, that is, 
A sequence of random variables,



Before giving you some examples let me make an statement that almost sure convergence implies the convergence in probability, and the convergence in probability implies the convergence in the distribution, so almost sure convergence is the strongest type of convergence among these while convergence in distribution is the weakest type. In fact, convergence in the distribution is completely different type of convergence, in this case we do not care for the convergence of random variables instead of their distribution functions. It is also important because sometimes it is much more desirable to know about distributions from the observed samples and that is the crux of the elegant Central limit theorem.
Example: Consider a sequence of random variables 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![X_1(x)=I_{[0,1]},X_2(x)=I_{[0,1/2]},X_3(x)=I_{[1/2,1]}](https://s0.wp.com/latex.php?latex=X_1%28x%29%3DI_%7B%5B0%2C1%5D%7D%2CX_2%28x%29%3DI_%7B%5B0%2C1%2F2%5D%7D%2CX_3%28x%29%3DI_%7B%5B1%2F2%2C1%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![X_4(x)=I_{[0,1/3]},X_5(x)=I_{[1/3,2/3]},X_6(x)=I_{[2/3,1]}](https://s0.wp.com/latex.php?latex=X_4%28x%29%3DI_%7B%5B0%2C1%2F3%5D%7D%2CX_5%28x%29%3DI_%7B%5B1%2F3%2C2%2F3%5D%7D%2CX_6%28x%29%3DI_%7B%5B2%2F3%2C1%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
You can observe that for any value of 





What do we mean by iid random sample?
The random variables 

Law of large numbers
There are two forms of Law of large numbers, weak and strong. The Strong law of large numbers implies the Weak law of large numbers because in the Weak law the convergence is in the probability while for the Strong law the convergence is almost sure convergence. The proof of the Weak law follows almost immediately from Chebyshev’s inequality while the proof for the Strong law is not that simple. So what are these laws? In simple words, they say that the sample mean converges to the population mean for large enough samples, and according to their convergence we have the weak or the strong law. Mathematically, let 
![E[X_i]=\mu](https://s0.wp.com/latex.php?latex=E%5BX_i%5D%3D%5Cmu&bg=ffffff&fg=000&s=0&c=20201002)



Weak law of large numbers (WLLN):

Strong law of large numbers (SLLN):

The beauty of these theorems is that they give an interpretation of probability in frequentist terms, that is, consider Bernoulli trial with 



Central limit theorem
This theorem abbreviately known as CLT deals with the convergence in distribution for the iid random samples. This theorems is used in almost all of the hypothesis testing problems where we do not know the distribution but have some large sample. It says that the distribution of the sample mean converges to the normal distribution for large enough samples. Now suppose 


Consider the following histogram of random samples of uniform distribution for different sample mean calculated for sample sizes 
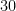

References:
Probability and Measure by Patrick Billingsley

Statistical Inference by George Casella and Roger Berger


Leave a comment