We are going to discuss the continuous distributions in this blog. I will provide you some of their basic properties with pdfs of each without going into a lot of details. The topics of discussion are as follows:
Normal Distribution
The normal distribution is the most widely used distribution in the statistics and many other applications from communication to finance, from sociology to all forms of science. It starts from the work of Abraham de Moivre who studied it as an approximation tool for binomial distribution, later which became Laplace-de Moivre theorem, an initial version of the central limit theorem. Also the great Gauss studied it as he was studying the movements of the planets and he figured out that the errors in measurement follow the normal curve or distribution, from then onwards many natural phenomenon were shown to follow normal distribution approximately. And in finance and many other fields modifications (read also as transformations) of normal distributions are generally good enough for the modeling purposes. It only requires two parameters to be defined, mean and variance or standard deviation. The pdf of normal distribution is given by, 


When 





![E[X]=\mu](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D%5Cmu&bg=ffffff&fg=000&s=0&c=20201002)

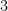

Lognormal Distribution
The lognormal distribution basically means a distribution whose log is normal, i.e. we say a random variable 


It is also defined using the mean and variance of the underlying normal distribution. It is an important distribution in finance because it is generally assumed that 
![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)



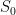








Cauchy distribution
It is one of the interesting distribution in the sense that the mean (in fact, no moments exist) does not exist. It has bell-shaped symmetric curve centered at the median which in the following diagram is at the zero. It is similar to normal but it has thick tails. The general form of the pdf is given by the two parameters, 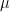


When 

![E[X]=\frac{1}{\pi}\int_{-\infty}^{\infty}\frac{x}{1+x^2} dx=\frac{1}{\pi}\int_{0}^{\infty}\frac{x}{1+x^2} dx+\frac{1}{\pi}\int_{-\infty}^{0}\frac{x}{1+x^2} dx](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D%5Cfrac%7B1%7D%7B%5Cpi%7D%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D%5Cfrac%7Bx%7D%7B1%2Bx%5E2%7D+dx%3D%5Cfrac%7B1%7D%7B%5Cpi%7D%5Cint_%7B0%7D%5E%7B%5Cinfty%7D%5Cfrac%7Bx%7D%7B1%2Bx%5E2%7D+dx%2B%5Cfrac%7B1%7D%7B%5Cpi%7D%5Cint_%7B-%5Cinfty%7D%5E%7B0%7D%5Cfrac%7Bx%7D%7B1%2Bx%5E2%7D+dx&bg=ffffff&fg=000&s=0&c=20201002)
here the first part of the integral is infinity and also the second part of the integral is negative infinity, so that the mean is neither finite nor it is infinite, hence it is undefined. On such kind of distributions, one can not apply Central limit theorem.
Actually there is interesting fact that this distribution was first published by the mathematician Poisson but Cauchy another mathematician got involved in some controversy and got the distribution named after him. This is an instance of Stigler’s law of Eponymy which basically says that no discovery is named after its actual discoverer, for examples you can see this list.

Gamma Distribution
The general form of the gamma distribution is given by the two parameters, 







It is one of the useful family of distributions, many distributions are formed using this distributions which would be the topic our next blog on continuous distributions, for example, for 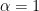
![E[X]=\alpha \beta](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D%5Calpha+%5Cbeta&bg=ffffff&fg=000&s=0&c=20201002)


Beta Distribution
The beta distribution is a continuous distribution on 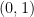



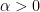


The expectation and variance of this is given by the following:
![E[X]=\frac{\alpha}{\alpha+\beta}](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D%5Cfrac%7B%5Calpha%7D%7B%5Calpha%2B%5Cbeta%7D&bg=ffffff&fg=000&s=0&c=20201002)

It is used as conjugate prior for binomial distribution, where conjugate priors are prior probabilities used in Bayesian inference, because the posterior probability is again has the form of the beta distribution.

Reference:
George Casella and Roger L. Berger, Statistical Inference, second Edition

Sheldon Ross, A First Course in Probability


Leave a comment