In this post, we are going to talk about some more discrete distributions and their uses. We will discuss the following distributions:
Categorical distribution
This is the generalization of Bernoulli distribution, in the sense that we now have k mutually exclusive outcomes, out of which only one occurs at a time i.e. they take values in 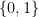 but with only one outcome taking value as 1(success) at a time (such variables are called as categorical variables, hence the name categorical distribution), with probabilities
but with only one outcome taking value as 1(success) at a time (such variables are called as categorical variables, hence the name categorical distribution), with probabilities  such that
such that  . It is sometimes called as multinoulli distribution to emphasize the generalization to the Bernoulli distribution in similar vein to the multinomial and binomial distributions. In machine learning parlance, it is used in one-hot encoding and classification problems. Given the probabilities and categories as above, the pmf for this distribution is given by,
. It is sometimes called as multinoulli distribution to emphasize the generalization to the Bernoulli distribution in similar vein to the multinomial and binomial distributions. In machine learning parlance, it is used in one-hot encoding and classification problems. Given the probabilities and categories as above, the pmf for this distribution is given by, ![\prod_{i=1}^k p_i^{[x=i]}](https://s0.wp.com/latex.php?latex=%5Cprod_%7Bi%3D1%7D%5Ek+p_i%5E%7B%5Bx%3Di%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) , where
, where ![[x=i] =1](https://s0.wp.com/latex.php?latex=%5Bx%3Di%5D+%3D1&bg=ffffff&fg=000&s=0&c=20201002) if true else
if true else  ,
,  is the category. This bracket is called as Iverson bracket.
is the category. This bracket is called as Iverson bracket.
Multinomial distribution
This is nothing but the generalization of the binomial distribution i.e. we now have k mutually exclusive outcomes instead of just two and we calculate the probability of different number of these k cases occurring. Suppose n to be the number of trials, k to be the number of outcomes, let to be the probability of  events occurring respectively such that ,
events occurring respectively such that ,  to be the number of times outcome occurs respectively such that
to be the number of times outcome occurs respectively such that  . Then the probability of first event happening
. Then the probability of first event happening  times, second event happening
times, second event happening 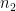 times and so on, is given by
times and so on, is given by  . This collection of probabilities is called as the multinomial distribution and using multinomial expansion of
. This collection of probabilities is called as the multinomial distribution and using multinomial expansion of  , we can show that this collection is a pmf (probability mass function). When the number of trials i.e.
, we can show that this collection is a pmf (probability mass function). When the number of trials i.e. 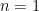 , we get categorical distribution as a special case of multinomial distribution. The point to be noted here is that multinomial distribution is an example of multivariate distribution, in simple words it is in multidimensional or vector form. We would discuss them later in details, so that is why I am not talking about its mean vector, variance vector here. When we sample using multinomial distribution it is called as sampling with replacement because in each draw we calculate probabilities based on
, we get categorical distribution as a special case of multinomial distribution. The point to be noted here is that multinomial distribution is an example of multivariate distribution, in simple words it is in multidimensional or vector form. We would discuss them later in details, so that is why I am not talking about its mean vector, variance vector here. When we sample using multinomial distribution it is called as sampling with replacement because in each draw we calculate probabilities based on  trials.
trials.
Hypergeometric distribution
Suppose we have balls out of which are red and  are black. Now we want to choose
are black. Now we want to choose  balls at random such that it contains
balls at random such that it contains  number of red balls, choosing both kind of balls is equally likely. What would be the probability of such an event? We can choose red balls from balls in
number of red balls, choosing both kind of balls is equally likely. What would be the probability of such an event? We can choose red balls from balls in  ways and
ways and  black balls from
black balls from  balls in
balls in  ways. Finally we can have any combination of these chosen red and black balls so that total number of ways red balls and black balls are chosen is
ways. Finally we can have any combination of these chosen red and black balls so that total number of ways red balls and black balls are chosen is  . So the probability of such an event is given by, say
. So the probability of such an event is given by, say  . The collection of these probabilities define hypergeometric distribution. Using Vandermonde’s identity i.e.
. The collection of these probabilities define hypergeometric distribution. Using Vandermonde’s identity i.e.  , one can show that this collection of probabilities is, in fact, a pmf. When we sample using hypergeometric distribution, it is a sampling without replacement as we are not replacing the balls taken out with the same ones. There is a famous anecdotal story associated with it, where a lady tastes the tea prepared and calls out whether tea was added first or the milk was added first. It is said that Fischer conducted the experiment with 8 samples of which 4 were tea first and 4 were milk first, arranged in random order. She was able to predict all of them correctly which has probability of
, one can show that this collection of probabilities is, in fact, a pmf. When we sample using hypergeometric distribution, it is a sampling without replacement as we are not replacing the balls taken out with the same ones. There is a famous anecdotal story associated with it, where a lady tastes the tea prepared and calls out whether tea was added first or the milk was added first. It is said that Fischer conducted the experiment with 8 samples of which 4 were tea first and 4 were milk first, arranged in random order. She was able to predict all of them correctly which has probability of  if done by random guessing, which meant she was most probably not doing random guessing.
if done by random guessing, which meant she was most probably not doing random guessing.
We can easily do sampling of these distributions in R or Python using their statistical libraries, just google them w.r.t. the programming language you want to sample, eg.,numpy,rhypergeom.
References:
George Casella and Roger L. Berger, Statistical Inference, second Edition
William Feller, An Introduction to Probability Theory and Its Applications, Volume I, Third Edition, John Wiley & Sons

Leave a comment